statsmodels 中的预测¶
本笔记本介绍了使用 statsmodels 中的时间序列模型进行预测。
注意:本笔记本仅适用于状态空间模型类,包括:
sm.tsa.SARIMAXsm.tsa.UnobservedComponentssm.tsa.VARMAXsm.tsa.DynamicFactor
[1]:
%matplotlib inline
import numpy as np
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
macrodata = sm.datasets.macrodata.load_pandas().data
macrodata.index = pd.period_range('1959Q1', '2009Q3', freq='Q')
基本示例¶
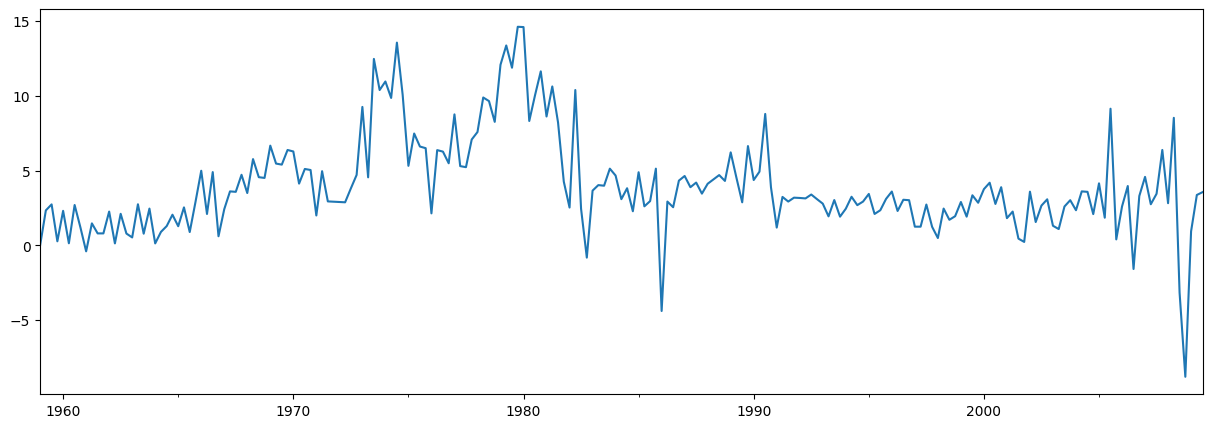
一个简单的例子是使用 AR(1) 模型来预测通货膨胀。在预测之前,让我们先看一下这个序列
[2]:
endog = macrodata['infl']
endog.plot(figsize=(15, 5))
[2]:
<Axes: >
构建和估计模型¶
下一步是制定我们想要用于预测的计量经济模型。在本例中,我们将使用 statsmodels 中的 SARIMAX 类来使用 AR(1) 模型。
构建模型后,我们需要估计其参数。这是使用 fit 方法完成的。 summary 方法生成了一些方便的表格,显示了结果。
[3]:
# Construct the model
mod = sm.tsa.SARIMAX(endog, order=(1, 0, 0), trend='c')
# Estimate the parameters
res = mod.fit()
print(res.summary())
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 3 M = 10
At X0 0 variables are exactly at the bounds
At iterate 0 f= 2.32873D+00 |proj g|= 8.23649D-03
At iterate 5 f= 2.32864D+00 |proj g|= 1.41994D-03
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
3 8 10 1 0 0 5.820D-06 2.329D+00
F = 2.3286389358138617
CONVERGENCE: NORM_OF_PROJECTED_GRADIENT_<=_PGTOL
SARIMAX Results
==============================================================================
Dep. Variable: infl No. Observations: 203
Model: SARIMAX(1, 0, 0) Log Likelihood -472.714
Date: Thu, 03 Oct 2024 AIC 951.427
Time: 16:07:30 BIC 961.367
Sample: 03-31-1959 HQIC 955.449
- 09-30-2009
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
intercept 1.3962 0.254 5.488 0.000 0.898 1.895
ar.L1 0.6441 0.039 16.482 0.000 0.568 0.721
sigma2 6.1519 0.397 15.487 0.000 5.373 6.930
===================================================================================
Ljung-Box (L1) (Q): 8.43 Jarque-Bera (JB): 68.45
Prob(Q): 0.00 Prob(JB): 0.00
Heteroskedasticity (H): 1.47 Skew: -0.22
Prob(H) (two-sided): 0.12 Kurtosis: 5.81
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
This problem is unconstrained.
预测¶
使用结果对象中的 forecast 或 get_forecast 方法生成样本外预测。
forecast 方法只给出点预测。
[4]:
# The default is to get a one-step-ahead forecast:
print(res.forecast())
2009Q4 3.68921
Freq: Q-DEC, dtype: float64
get_forecast 方法更通用,也可以用来构建置信区间。
[5]:
# Here we construct a more complete results object.
fcast_res1 = res.get_forecast()
# Most results are collected in the `summary_frame` attribute.
# Here we specify that we want a confidence level of 90%
print(fcast_res1.summary_frame(alpha=0.10))
infl mean mean_se mean_ci_lower mean_ci_upper
2009Q4 3.68921 2.480302 -0.390523 7.768943
默认置信水平为 95%,但可以通过设置 alpha 参数来控制,其中置信水平定义为 \((1 - \alpha) \times 100\%\)。在上面的例子中,我们指定了 90% 的置信水平,使用 alpha=0.10。
指定预测数量¶
forecast 和 get_forecast 函数都接受一个参数,用于指示所需的预测步骤数量。这个参数的一个选项是始终提供一个整数,描述您希望预测的步数。
[6]:
print(res.forecast(steps=2))
2009Q4 3.689210
2010Q1 3.772434
Freq: Q-DEC, Name: predicted_mean, dtype: float64
[7]:
fcast_res2 = res.get_forecast(steps=2)
# Note: since we did not specify the alpha parameter, the
# confidence level is at the default, 95%
print(fcast_res2.summary_frame())
infl mean mean_se mean_ci_lower mean_ci_upper
2009Q4 3.689210 2.480302 -1.172092 8.550512
2010Q1 3.772434 2.950274 -2.009996 9.554865
但是,如果您的数据包含具有定义频率的 Pandas 索引(有关更多信息,请参见关于索引的结尾部分),那么您可以选择指定要生成预测的日期
[8]:
print(res.forecast('2010Q2'))
2009Q4 3.689210
2010Q1 3.772434
2010Q2 3.826039
Freq: Q-DEC, Name: predicted_mean, dtype: float64
[9]:
fcast_res3 = res.get_forecast('2010Q2')
print(fcast_res3.summary_frame())
infl mean mean_se mean_ci_lower mean_ci_upper
2009Q4 3.689210 2.480302 -1.172092 8.550512
2010Q1 3.772434 2.950274 -2.009996 9.554865
2010Q2 3.826039 3.124571 -2.298008 9.950087
绘制数据、预测和置信区间¶
通常,绘制数据、预测和置信区间非常有用。有很多方法可以做到这一点,但这里有一个例子
[10]:
fig, ax = plt.subplots(figsize=(15, 5))
# Plot the data (here we are subsetting it to get a better look at the forecasts)
endog.loc['1999':].plot(ax=ax)
# Construct the forecasts
fcast = res.get_forecast('2011Q4').summary_frame()
fcast['mean'].plot(ax=ax, style='k--')
ax.fill_between(fcast.index, fcast['mean_ci_lower'], fcast['mean_ci_upper'], color='k', alpha=0.1);
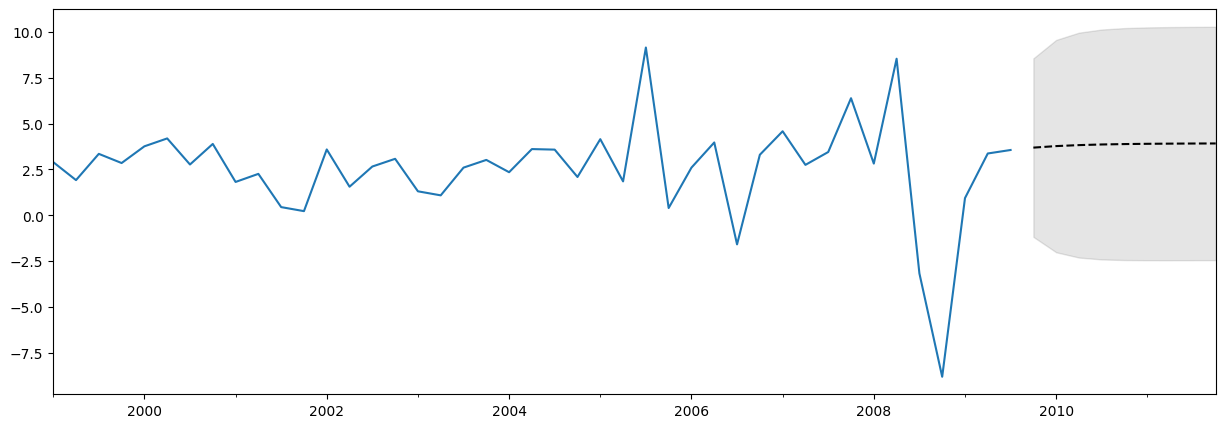
关于对预测的期望说明¶
上面的预测可能看起来不太令人印象深刻,因为它几乎是一条直线。这是因为这是一个非常简单的单变量预测模型。但是,请记住,这些简单的预测模型可能非常具有竞争力。
预测与预测¶
结果对象还包含两种方法,这两种方法都允许进行样本内拟合值和样本外预测。它们是 predict 和 get_prediction。 predict 方法只返回点预测(类似于 forecast),而 get_prediction 方法还返回其他结果(类似于 get_forecast)。
一般来说,如果您感兴趣的是样本外预测,那么坚持使用 forecast 和 get_forecast 方法更容易。
交叉验证¶
注意:本节中使用的一些函数是在 statsmodels v0.11.0 中首次引入的。
一个常见的用例是通过执行以下过程递归地执行 h 步超前预测来交叉验证预测方法
在训练样本上拟合模型参数
从该样本的末尾生成 h 步超前预测
将预测与测试数据集进行比较以计算误差率
扩展样本以包含下一个观察结果,并重复
经济学家有时称之为伪样本外预测评估练习或时间序列交叉验证。
示例¶
我们将使用上面的通货膨胀数据集进行一项非常简单的此类练习。完整数据集包含 203 个观察结果,为了说明,我们将使用前 80% 作为我们的训练样本,并且只考虑一步超前预测。
上面过程的单次迭代如下所示
[11]:
# Step 1: fit model parameters w/ training sample
training_obs = int(len(endog) * 0.8)
training_endog = endog[:training_obs]
training_mod = sm.tsa.SARIMAX(
training_endog, order=(1, 0, 0), trend='c')
training_res = training_mod.fit()
# Print the estimated parameters
print(training_res.params)
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 3 M = 10
At X0 0 variables are exactly at the bounds
At iterate 0 f= 2.23132D+00 |proj g|= 1.09171D-02
At iterate 5 f= 2.23109D+00 |proj g|= 3.93608D-05
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
3 6 8 1 0 0 7.066D-07 2.231D+00
F = 2.2310884444664758
CONVERGENCE: NORM_OF_PROJECTED_GRADIENT_<=_PGTOL
intercept 1.162076
ar.L1 0.724242
sigma2 5.051600
dtype: float64
This problem is unconstrained.
[12]:
# Step 2: produce one-step-ahead forecasts
fcast = training_res.forecast()
# Step 3: compute root mean square forecasting error
true = endog.reindex(fcast.index)
error = true - fcast
# Print out the results
print(pd.concat([true.rename('true'),
fcast.rename('forecast'),
error.rename('error')], axis=1))
true forecast error
1999Q3 3.35 2.55262 0.79738
要添加另一个观察结果,我们可以使用 append 或 extend 结果方法。两种方法都可以生成相同的预测,但它们在可用的其他结果方面有所不同
append是更完整的方法。它始终存储所有训练观察结果的结果,并可以选择允许在给定新观察结果的情况下重新拟合模型参数(请注意,默认情况下不重新拟合参数)。extend是一种更快的速度,如果训练样本非常大,则可能很有用。它只存储新观察结果的结果,并且不允许重新拟合模型参数(即您必须使用之前样本上估计的参数)。
如果您的训练样本相对较小(例如,少于几千个观察结果),或者如果您想计算尽可能准确的预测,那么您应该使用 append 方法。但是,如果该方法不可行(例如,因为您拥有非常大的训练样本),或者如果您对稍微次优的预测可以接受(因为参数估计会稍微过时),那么您可以考虑使用 extend 方法。
第二次迭代,使用 append 方法并重新拟合参数,将如下所示(请再次注意, append 的默认值不重新拟合参数,但我们已使用 refit=True 参数覆盖了这一点)
[13]:
# Step 1: append a new observation to the sample and refit the parameters
append_res = training_res.append(endog[training_obs:training_obs + 1], refit=True)
# Print the re-estimated parameters
print(append_res.params)
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 3 M = 10
At X0 0 variables are exactly at the bounds
At iterate 0 f= 2.22839D+00 |proj g|= 2.38555D-03
At iterate 5 f= 2.22838D+00 |proj g|= 9.80105D-08
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
3 5 8 1 0 0 9.801D-08 2.228D+00
F = 2.2283821699856410
CONVERGENCE: NORM_OF_PROJECTED_GRADIENT_<=_PGTOL
intercept 1.171544
ar.L1 0.723152
sigma2 5.024580
dtype: float64
This problem is unconstrained.
注意,这些估计参数与我们最初估计的参数略有不同。使用新的结果对象, append_res,我们可以计算从比上一次调用更早的一个观察结果开始的预测
[14]:
# Step 2: produce one-step-ahead forecasts
fcast = append_res.forecast()
# Step 3: compute root mean square forecasting error
true = endog.reindex(fcast.index)
error = true - fcast
# Print out the results
print(pd.concat([true.rename('true'),
fcast.rename('forecast'),
error.rename('error')], axis=1))
true forecast error
1999Q4 2.85 3.594102 -0.744102
将它们放在一起,我们可以执行递归预测评估练习,如下所示
[15]:
# Setup forecasts
nforecasts = 3
forecasts = {}
# Get the number of initial training observations
nobs = len(endog)
n_init_training = int(nobs * 0.8)
# Create model for initial training sample, fit parameters
init_training_endog = endog.iloc[:n_init_training]
mod = sm.tsa.SARIMAX(training_endog, order=(1, 0, 0), trend='c')
res = mod.fit()
# Save initial forecast
forecasts[training_endog.index[-1]] = res.forecast(steps=nforecasts)
# Step through the rest of the sample
for t in range(n_init_training, nobs):
# Update the results by appending the next observation
updated_endog = endog.iloc[t:t+1]
res = res.append(updated_endog, refit=False)
# Save the new set of forecasts
forecasts[updated_endog.index[0]] = res.forecast(steps=nforecasts)
# Combine all forecasts into a dataframe
forecasts = pd.concat(forecasts, axis=1)
print(forecasts.iloc[:5, :5])
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 3 M = 10
At X0 0 variables are exactly at the bounds
At iterate 0 f= 2.23132D+00 |proj g|= 1.09171D-02
This problem is unconstrained.
At iterate 5 f= 2.23109D+00 |proj g|= 3.93608D-05
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
3 6 8 1 0 0 7.066D-07 2.231D+00
F = 2.2310884444664758
CONVERGENCE: NORM_OF_PROJECTED_GRADIENT_<=_PGTOL
1999Q2 1999Q3 1999Q4 2000Q1 2000Q2
1999Q3 2.552620 NaN NaN NaN NaN
1999Q4 3.010790 3.588286 NaN NaN NaN
2000Q1 3.342616 3.760863 3.226165 NaN NaN
2000Q2 NaN 3.885850 3.498599 3.885225 NaN
2000Q3 NaN NaN 3.695908 3.975918 4.196649
我们现在有一组三个预测,这些预测在 1999Q2 到 2009Q3 的每个时间点进行。我们可以通过从该时间点的 endog 的实际值中减去每个预测来构造预测误差。
[16]:
# Construct the forecast errors
forecast_errors = forecasts.apply(lambda column: endog - column).reindex(forecasts.index)
print(forecast_errors.iloc[:5, :5])
1999Q2 1999Q3 1999Q4 2000Q1 2000Q2
1999Q3 0.797380 NaN NaN NaN NaN
1999Q4 -0.160790 -0.738286 NaN NaN NaN
2000Q1 0.417384 -0.000863 0.533835 NaN NaN
2000Q2 NaN 0.304150 0.691401 0.304775 NaN
2000Q3 NaN NaN -0.925908 -1.205918 -1.426649
为了评估我们的预测,我们通常希望查看像均方根误差这样的摘要值。在这里,我们可以通过首先展平预测误差以使它们按范围索引,然后计算每个范围的均方根误差来计算它。
[17]:
# Reindex the forecasts by horizon rather than by date
def flatten(column):
return column.dropna().reset_index(drop=True)
flattened = forecast_errors.apply(flatten)
flattened.index = (flattened.index + 1).rename('horizon')
print(flattened.iloc[:3, :5])
1999Q2 1999Q3 1999Q4 2000Q1 2000Q2
horizon
1 0.797380 -0.738286 0.533835 0.304775 -1.426649
2 -0.160790 -0.000863 0.691401 -1.205918 -0.311464
3 0.417384 0.304150 -0.925908 -0.151602 -2.384952
[18]:
# Compute the root mean square error
rmse = (flattened**2).mean(axis=1)**0.5
print(rmse)
horizon
1 3.292700
2 3.421808
3 3.280012
dtype: float64
使用 extend¶
我们可以检查一下,如果我们改用 extend 方法,我们会得到类似的预测,但它们与使用 append 以及 refit=True 参数时不完全相同。这是因为 extend 不会根据新观察结果重新估计参数。
[19]:
# Setup forecasts
nforecasts = 3
forecasts = {}
# Get the number of initial training observations
nobs = len(endog)
n_init_training = int(nobs * 0.8)
# Create model for initial training sample, fit parameters
init_training_endog = endog.iloc[:n_init_training]
mod = sm.tsa.SARIMAX(training_endog, order=(1, 0, 0), trend='c')
res = mod.fit()
# Save initial forecast
forecasts[training_endog.index[-1]] = res.forecast(steps=nforecasts)
# Step through the rest of the sample
for t in range(n_init_training, nobs):
# Update the results by appending the next observation
updated_endog = endog.iloc[t:t+1]
res = res.extend(updated_endog)
# Save the new set of forecasts
forecasts[updated_endog.index[0]] = res.forecast(steps=nforecasts)
# Combine all forecasts into a dataframe
forecasts = pd.concat(forecasts, axis=1)
print(forecasts.iloc[:5, :5])
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 3 M = 10
At X0 0 variables are exactly at the bounds
At iterate 0 f= 2.23132D+00 |proj g|= 1.09171D-02
At iterate 5 f= 2.23109D+00 |proj g|= 3.93608D-05
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
3 6 8 1 0 0 7.066D-07 2.231D+00
F = 2.2310884444664758
CONVERGENCE: NORM_OF_PROJECTED_GRADIENT_<=_PGTOL
This problem is unconstrained.
1999Q2 1999Q3 1999Q4 2000Q1 2000Q2
1999Q3 2.552620 NaN NaN NaN NaN
1999Q4 3.010790 3.588286 NaN NaN NaN
2000Q1 3.342616 3.760863 3.226165 NaN NaN
2000Q2 NaN 3.885850 3.498599 3.885225 NaN
2000Q3 NaN NaN 3.695908 3.975918 4.196649
[20]:
# Construct the forecast errors
forecast_errors = forecasts.apply(lambda column: endog - column).reindex(forecasts.index)
print(forecast_errors.iloc[:5, :5])
1999Q2 1999Q3 1999Q4 2000Q1 2000Q2
1999Q3 0.797380 NaN NaN NaN NaN
1999Q4 -0.160790 -0.738286 NaN NaN NaN
2000Q1 0.417384 -0.000863 0.533835 NaN NaN
2000Q2 NaN 0.304150 0.691401 0.304775 NaN
2000Q3 NaN NaN -0.925908 -1.205918 -1.426649
[21]:
# Reindex the forecasts by horizon rather than by date
def flatten(column):
return column.dropna().reset_index(drop=True)
flattened = forecast_errors.apply(flatten)
flattened.index = (flattened.index + 1).rename('horizon')
print(flattened.iloc[:3, :5])
1999Q2 1999Q3 1999Q4 2000Q1 2000Q2
horizon
1 0.797380 -0.738286 0.533835 0.304775 -1.426649
2 -0.160790 -0.000863 0.691401 -1.205918 -0.311464
3 0.417384 0.304150 -0.925908 -0.151602 -2.384952
[22]:
# Compute the root mean square error
rmse = (flattened**2).mean(axis=1)**0.5
print(rmse)
horizon
1 3.292700
2 3.421808
3 3.280012
dtype: float64
通过不重新估计参数,我们的预测略差(每个范围的均方根误差更高)。但是,即使只有 200 个数据点,该过程也更快。在上面的单元格上使用 %%timeit 单元格魔法,我们发现使用 extend 的运行时间为 570 毫秒,而使用 append 以及 refit=True 的运行时间为 1.7 秒。(请注意,使用 extend 也比使用 append 以及 refit=False 更快)。
索引¶
在本笔记本中,我们一直在使用具有关联频率的 Pandas 日期索引。如您所见,此索引将我们的数据标记为按季度频率,介于 1959Q1 和 2009Q3 之间。
[23]:
print(endog.index)
PeriodIndex(['1959Q1', '1959Q2', '1959Q3', '1959Q4', '1960Q1', '1960Q2',
'1960Q3', '1960Q4', '1961Q1', '1961Q2',
...
'2007Q2', '2007Q3', '2007Q4', '2008Q1', '2008Q2', '2008Q3',
'2008Q4', '2009Q1', '2009Q2', '2009Q3'],
dtype='period[Q-DEC]', length=203)
在大多数情况下,如果您的数据具有关联的日期/时间索引,并且具有定义的频率(如季度、每月等),那么最好确保您的数据是具有适当索引的 Pandas 系列。以下是三个示例。
[24]:
# Annual frequency, using a PeriodIndex
index = pd.period_range(start='2000', periods=4, freq='Y')
endog1 = pd.Series([1, 2, 3, 4], index=index)
print(endog1.index)
PeriodIndex(['2000', '2001', '2002', '2003'], dtype='period[Y-DEC]')
[25]:
# Quarterly frequency, using a DatetimeIndex
index = pd.date_range(start='2000', periods=4, freq='QS')
endog2 = pd.Series([1, 2, 3, 4], index=index)
print(endog2.index)
DatetimeIndex(['2000-01-01', '2000-04-01', '2000-07-01', '2000-10-01'], dtype='datetime64[ns]', freq='QS-JAN')
[26]:
# Monthly frequency, using a DatetimeIndex
index = pd.date_range(start='2000', periods=4, freq='ME')
endog3 = pd.Series([1, 2, 3, 4], index=index)
print(endog3.index)
DatetimeIndex(['2000-01-31', '2000-02-29', '2000-03-31', '2000-04-30'], dtype='datetime64[ns]', freq='ME')
事实上,如果您的数据具有关联的日期/时间索引,即使它没有定义的频率,最好使用它。这种索引的示例如下 - 注意它具有 freq=None
[27]:
index = pd.DatetimeIndex([
'2000-01-01 10:08am', '2000-01-01 11:32am',
'2000-01-01 5:32pm', '2000-01-02 6:15am'])
endog4 = pd.Series([0.2, 0.5, -0.1, 0.1], index=index)
print(endog4.index)
DatetimeIndex(['2000-01-01 10:08:00', '2000-01-01 11:32:00',
'2000-01-01 17:32:00', '2000-01-02 06:15:00'],
dtype='datetime64[ns]', freq=None)
您仍然可以将此数据传递给 statsmodels 的模型类,但您将收到以下警告,即没有找到频率数据。
[28]:
mod = sm.tsa.SARIMAX(endog4)
res = mod.fit()
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 2 M = 10
At X0 0 variables are exactly at the bounds
At iterate 0 f= 1.37900D-01 |proj g|= 4.66940D-01
/opt/hostedtoolcache/Python/3.10.15/x64/lib/python3.10/site-packages/statsmodels/tsa/base/tsa_model.py:473: ValueWarning: A date index has been provided, but it has no associated frequency information and so will be ignored when e.g. forecasting.
self._init_dates(dates, freq)
/opt/hostedtoolcache/Python/3.10.15/x64/lib/python3.10/site-packages/statsmodels/tsa/base/tsa_model.py:473: ValueWarning: A date index has been provided, but it has no associated frequency information and so will be ignored when e.g. forecasting.
self._init_dates(dates, freq)
This problem is unconstrained.
At iterate 5 f= 1.32476D-01 |proj g|= 6.00136D-06
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
2 5 10 1 0 0 6.001D-06 1.325D-01
F = 0.13247641992895681
CONVERGENCE: NORM_OF_PROJECTED_GRADIENT_<=_PGTOL
这意味着您无法通过日期指定预测步长,并且 forecast 和 get_forecast 方法的输出将没有关联的日期。原因是,如果没有给定的频率,就无法确定每个预测应该分配给哪个日期。在上面的示例中,索引的日期/时间戳没有模式,因此无法确定下一个日期/时间应该是什么(应该是 2000-01-02 的早上?下午?还是可能要等到 2000-01-03?)。
例如,如果我们预测一步向前
[29]:
res.forecast(1)
/opt/hostedtoolcache/Python/3.10.15/x64/lib/python3.10/site-packages/statsmodels/tsa/base/tsa_model.py:837: ValueWarning: No supported index is available. Prediction results will be given with an integer index beginning at `start`.
return get_prediction_index(
/opt/hostedtoolcache/Python/3.10.15/x64/lib/python3.10/site-packages/statsmodels/tsa/base/tsa_model.py:837: FutureWarning: No supported index is available. In the next version, calling this method in a model without a supported index will result in an exception.
return get_prediction_index(
[29]:
4 0.011866
dtype: float64
与新预测关联的索引是 4,因为如果给定数据具有整数索引,那将是下一个值。将给出警告,让用户知道索引不是日期/时间索引。
如果我们尝试使用日期指定预测的步骤,我们将收到以下异常
KeyError: 'The `end` argument could not be matched to a location related to the index of the data.'
[30]:
# Here we'll catch the exception to prevent printing too much of
# the exception trace output in this notebook
try:
res.forecast('2000-01-03')
except KeyError as e:
print(e)
'The `end` argument could not be matched to a location related to the index of the data.'
最终,使用没有关联日期/时间频率的数据,甚至使用根本没有索引的数据,例如 Numpy 数组,并没有错。但是,如果您能够使用具有关联频率的 Pandas 系列,您将有更多选项来指定您的预测,并获得具有更有用索引的结果。