滚动回归¶
滚动 OLS 在固定观测窗口上应用 OLS,然后在整个数据集上滚动(移动或滑动)窗口。关键参数是 window,它确定每次 OLS 回归中使用的观测值数量。默认情况下,RollingOLS 会删除窗口中的缺失值,因此会使用可用的数据点估计模型。
估计值对齐,以便使用数据点 \(i+1, i+2, ... i+window\) 估计的模型存储在位置 \(i+window\) 中。
首先导入本笔记本中使用的模块。
[1]:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pandas_datareader as pdr
import seaborn
import statsmodels.api as sm
from statsmodels.regression.rolling import RollingOLS
seaborn.set_style("darkgrid")
pd.plotting.register_matplotlib_converters()
%matplotlib inline
pandas-datareader 用于从 肯·弗伦奇的网站 下载数据。下载的两个数据集是 3 个 Fama-French 因子和 10 个行业投资组合。数据可从 1926 年开始使用。
数据是因子或行业投资组合的月度收益率。
[2]:
factors = pdr.get_data_famafrench("F-F_Research_Data_Factors", start="1-1-1926")[0]
factors.head()
/tmp/ipykernel_3995/1924419770.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
factors = pdr.get_data_famafrench("F-F_Research_Data_Factors", start="1-1-1926")[0]
/tmp/ipykernel_3995/1924419770.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
factors = pdr.get_data_famafrench("F-F_Research_Data_Factors", start="1-1-1926")[0]
[2]:
| Mkt-RF | SMB | HML | RF | |
|---|---|---|---|---|
| 日期 | ||||
| 1926-07 | 2.96 | -2.56 | -2.43 | 0.22 |
| 1926-08 | 2.64 | -1.17 | 3.82 | 0.25 |
| 1926-09 | 0.36 | -1.40 | 0.13 | 0.23 |
| 1926-10 | -3.24 | -0.09 | 0.70 | 0.32 |
| 1926-11 | 2.53 | -0.10 | -0.51 | 0.31 |
[3]:
industries = pdr.get_data_famafrench("10_Industry_Portfolios", start="1-1-1926")[0]
industries.head()
/tmp/ipykernel_3995/268191425.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
industries = pdr.get_data_famafrench("10_Industry_Portfolios", start="1-1-1926")[0]
/tmp/ipykernel_3995/268191425.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
industries = pdr.get_data_famafrench("10_Industry_Portfolios", start="1-1-1926")[0]
/tmp/ipykernel_3995/268191425.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
industries = pdr.get_data_famafrench("10_Industry_Portfolios", start="1-1-1926")[0]
/tmp/ipykernel_3995/268191425.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
industries = pdr.get_data_famafrench("10_Industry_Portfolios", start="1-1-1926")[0]
/tmp/ipykernel_3995/268191425.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
industries = pdr.get_data_famafrench("10_Industry_Portfolios", start="1-1-1926")[0]
/tmp/ipykernel_3995/268191425.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
industries = pdr.get_data_famafrench("10_Industry_Portfolios", start="1-1-1926")[0]
/tmp/ipykernel_3995/268191425.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
industries = pdr.get_data_famafrench("10_Industry_Portfolios", start="1-1-1926")[0]
/tmp/ipykernel_3995/268191425.py:1: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
industries = pdr.get_data_famafrench("10_Industry_Portfolios", start="1-1-1926")[0]
[3]:
| 非耐用品 | 耐用品 | 制造业 | 能源 | 高科技 | 电信 | 商店 | 医疗保健 | 公用事业 | 其他 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 日期 | ||||||||||
| 1926-07 | 1.45 | 15.55 | 4.69 | -1.18 | 2.90 | 0.83 | 0.11 | 1.77 | 7.04 | 2.13 |
| 1926-08 | 3.97 | 3.68 | 2.81 | 3.47 | 2.66 | 2.17 | -0.71 | 4.25 | -1.69 | 4.35 |
| 1926-09 | 1.14 | 4.80 | 1.15 | -3.39 | -0.38 | 2.41 | 0.21 | 0.69 | 2.04 | 0.29 |
| 1926-10 | -1.24 | -8.23 | -3.63 | -0.78 | -4.58 | -0.11 | -2.29 | -0.57 | -2.63 | -2.84 |
| 1926-11 | 5.20 | -0.19 | 4.10 | 0.01 | 4.71 | 1.63 | 6.43 | 5.42 | 3.71 | 2.11 |
第一个估计的模型是 CAPM 的滚动版本,它将科技行业的超额收益率回归到市场的超额收益率上。
窗口为 60 个月,因此在第一个 60 个月 (window) 后即可获得结果。前 59 个 (window - 1) 估计值全部填充为 nan。
[4]:
endog = industries.HiTec - factors.RF.values
exog = sm.add_constant(factors["Mkt-RF"])
rols = RollingOLS(endog, exog, window=60)
rres = rols.fit()
params = rres.params.copy()
params.index = np.arange(1, params.shape[0] + 1)
params.head()
[4]:
| 常数 | Mkt-RF | |
|---|---|---|
| 1 | NaN | NaN |
| 2 | NaN | NaN |
| 3 | NaN | NaN |
| 4 | NaN | NaN |
| 5 | NaN | NaN |
[5]:
params.iloc[57:62]
[5]:
| 常数 | Mkt-RF | |
|---|---|---|
| 58 | NaN | NaN |
| 59 | NaN | NaN |
| 60 | 0.876155 | 1.399240 |
| 61 | 0.879936 | 1.406578 |
| 62 | 0.953169 | 1.408826 |
[6]:
params.tail()
[6]:
| 常数 | Mkt-RF | |
|---|---|---|
| 1174 | 0.480235 | 1.089338 |
| 1175 | 0.552565 | 1.086061 |
| 1176 | 0.610923 | 1.090145 |
| 1177 | 0.517339 | 1.089693 |
| 1178 | 0.503159 | 1.088327 |
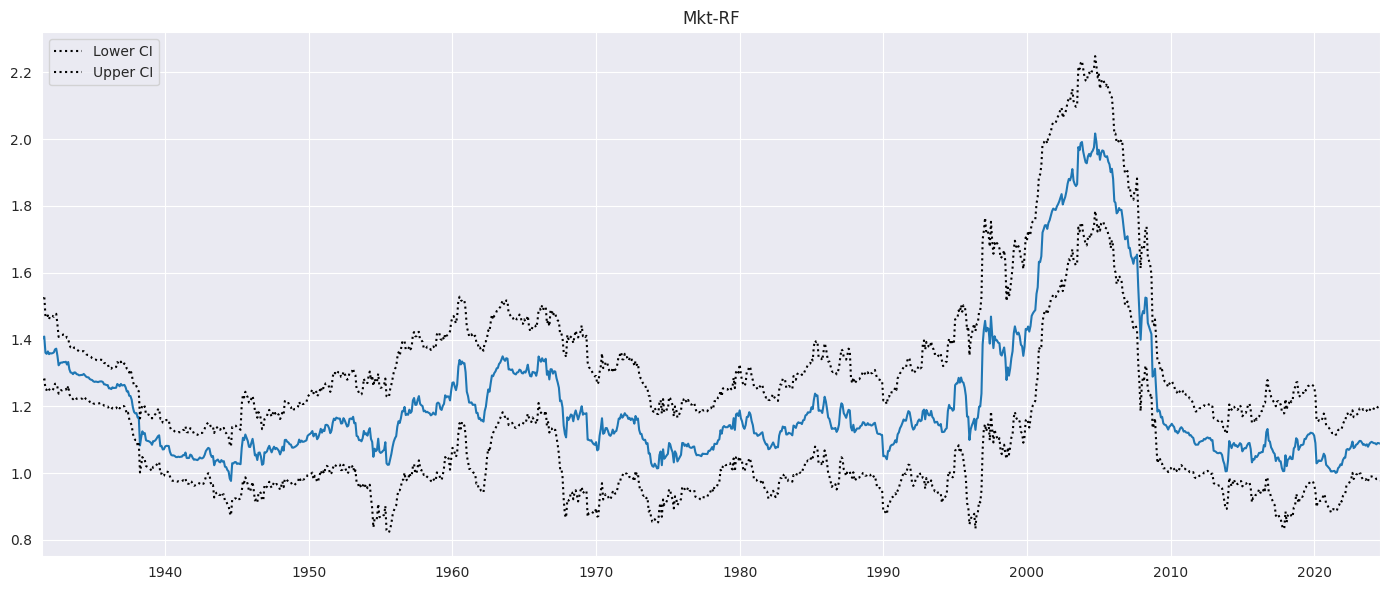
接下来,我们将市场负载与 95% 的逐点置信区间一起绘制。 alpha=False 省略常数列(如果存在)。
[7]:
fig = rres.plot_recursive_coefficient(variables=["Mkt-RF"], figsize=(14, 6))
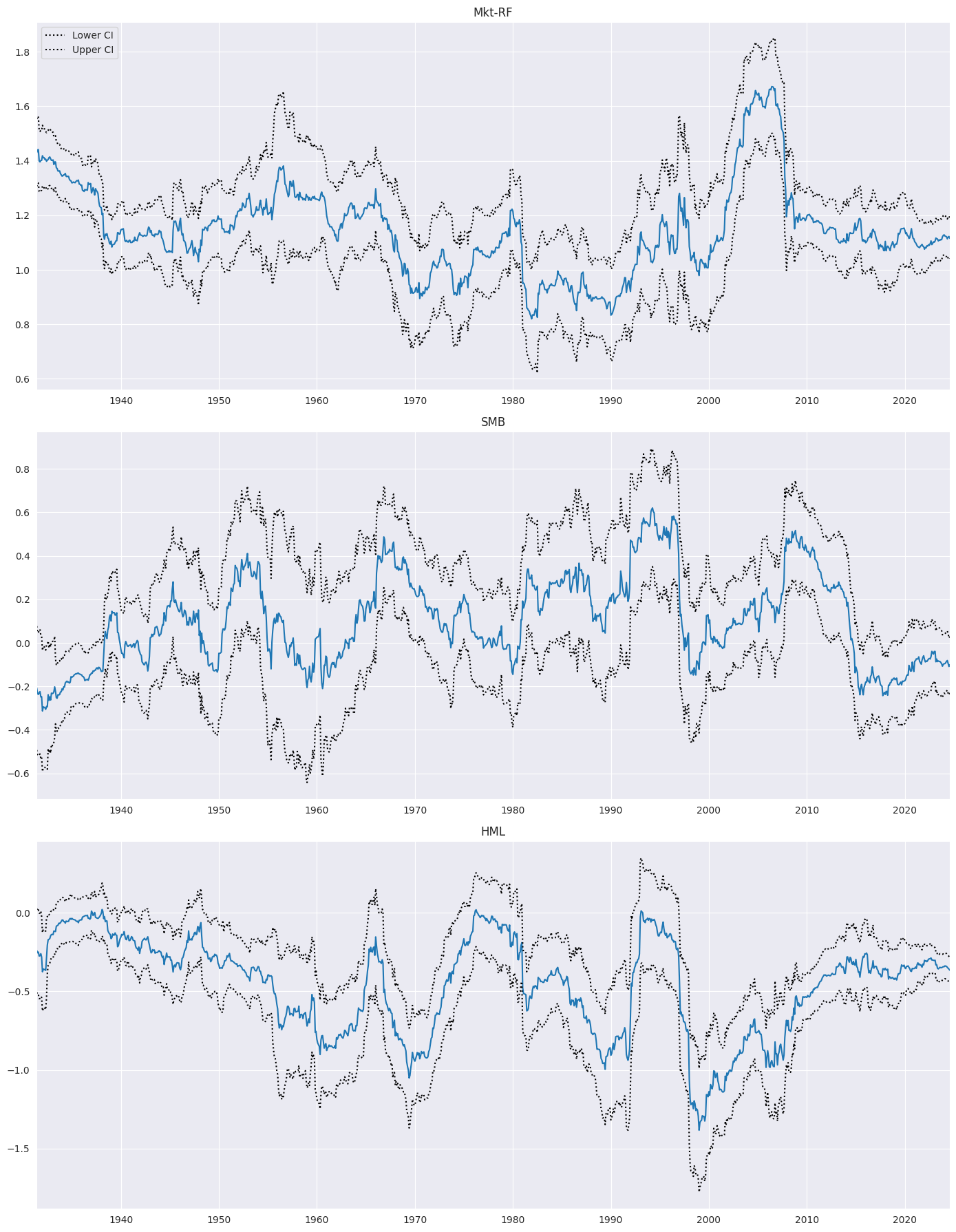
接下来,模型扩展到包括所有三个因子:超额市场、规模因子和价值因子。
[8]:
exog_vars = ["Mkt-RF", "SMB", "HML"]
exog = sm.add_constant(factors[exog_vars])
rols = RollingOLS(endog, exog, window=60)
rres = rols.fit()
fig = rres.plot_recursive_coefficient(variables=exog_vars, figsize=(14, 18))
公式¶
RollingOLS 和 RollingWLS 都支持使用公式接口的模型规范。下面的示例等效于之前估计的 3 因子模型。请注意,一个变量被重命名以具有有效的 Python 变量名。
[9]:
joined = pd.concat([factors, industries], axis=1)
joined["Mkt_RF"] = joined["Mkt-RF"]
mod = RollingOLS.from_formula("HiTec ~ Mkt_RF + SMB + HML", data=joined, window=60)
rres = mod.fit()
rres.params.tail()
[9]:
| 截距 | Mkt_RF | SMB | HML | |
|---|---|---|---|---|
| 日期 | ||||
| 2024-04 | 0.600109 | 1.121680 | -0.095098 | -0.344825 |
| 2024-05 | 0.682975 | 1.114558 | -0.091375 | -0.351516 |
| 2024-06 | 0.719744 | 1.121549 | -0.106960 | -0.357406 |
| 2024-07 | 0.674874 | 1.122952 | -0.115250 | -0.361814 |
| 2024-08 | 0.691445 | 1.116360 | -0.108656 | -0.368933 |
RollingWLS: 滚动加权最小二乘法¶
rolling 模块还提供 RollingWLS,它接受一个可选的 weights 输入来执行滚动加权最小二乘法。它产生的结果与应用于滚动数据窗口的 WLS 相匹配。
拟合选项¶
Fit 接受其他可选关键字来设置协方差估计器。仅支持两个估计器:'nonrobust'(经典 OLS 估计器)和 'HC0'(怀特异方差稳健估计器)。
您可以设置 params_only=True 仅估计模型参数。这比计算执行推断所需的全套值快得多。
最后,参数 reset 可以设置为正整数以控制非常长样本中的估计误差。 RollingOLS 在滚动时避免了完整的矩阵乘积,它只是在滚动样本时添加最新的观测值并删除被删除的观测值。设置 reset 每 reset 个周期使用完整的内积。在大多数应用程序中,此参数可以省略。
[10]:
%timeit rols.fit()
%timeit rols.fit(params_only=True)
321 ms ± 30.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
69.8 ms ± 8.5 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
扩展样本¶
可以扩展样本,直到有足够的观测值可用于完整窗口长度。在本示例中,我们从有 12 个观测值开始,然后增加样本,直到有 60 个观测值可用。第一个非 nan 值使用 12 个观测值计算,第二个使用 13 个,依此类推。所有其他估计值都使用 60 个观测值计算。
[11]:
res = RollingOLS(endog, exog, window=60, min_nobs=12, expanding=True).fit()
res.params.iloc[10:15]
[11]:
| 常数 | Mkt-RF | SMB | HML | |
|---|---|---|---|---|
| 日期 | ||||
| 1927-05 | NaN | NaN | NaN | NaN |
| 1927-06 | 1.560283 | 0.999383 | 1.351219 | -0.471879 |
| 1927-07 | 1.235899 | 1.294857 | 0.742924 | -0.540048 |
| 1927-08 | 1.249999 | 1.297546 | 0.752327 | -0.548306 |
| 1927-09 | 1.375626 | 1.286724 | 1.177758 | -0.609331 |
[12]:
res.nobs[10:15]
[12]:
Date
1927-05 0
1927-06 12
1927-07 13
1927-08 14
1927-09 15
Freq: M, dtype: int64